Why do ML engineers struggle to build trustworthy ML applications?
While research in ethics of AI increased significantly during the last years, practitioners tend to neglect the risks coming from inequity or unfairness of their ML components. This is one of the insights of the annual State of AI report for 2020 recently published by the Human-Centred Artificial Intelligence group from Stanford University.
Why does this gap exist between theory and practice, and how can it be closed?
In our own research (SE4ML), we have approached this issue from several angles, specifically for the major AI subarea machine learning (ML). On the one hand, we studied ML engineering practices and their level of adoption among ML engineering teams. On the other hand, we studied the requirements for trustworthy ML formulated by policy makers. Finally, we investigated the relative importance of a range of decision drivers for architects of ML systems.
As we discuss in more detail below, our overall conclusion is that ML engineering teams lack concrete courses of action for designing and building their systems, specifically to satisfy trustworthiness requirements, such as security, robustness, and fairness. Also, we can draw the conclusion that practitioners are aware of the ethical and robustness risks raised by improper development of ML components, but are currently constrained by more traditional concerns such as scaling their systems, or maintaining performance between training and testing.
What are ML engineering practices?
ML engineering is a discipline concerned with developing engineering principles for the design, development, operation and maintenance of software systems with ML components. In order to facilitate the adoption of engineering principles by practitioners, we have systematically distilled actionable engineering practices. On our website, we share the software engineering best practices for ML components. Moreover, we measure and publish the adoption rate of these practices and their perceived effects, in order to allow comparisons and assessments of teams of engineers building software with ML components.
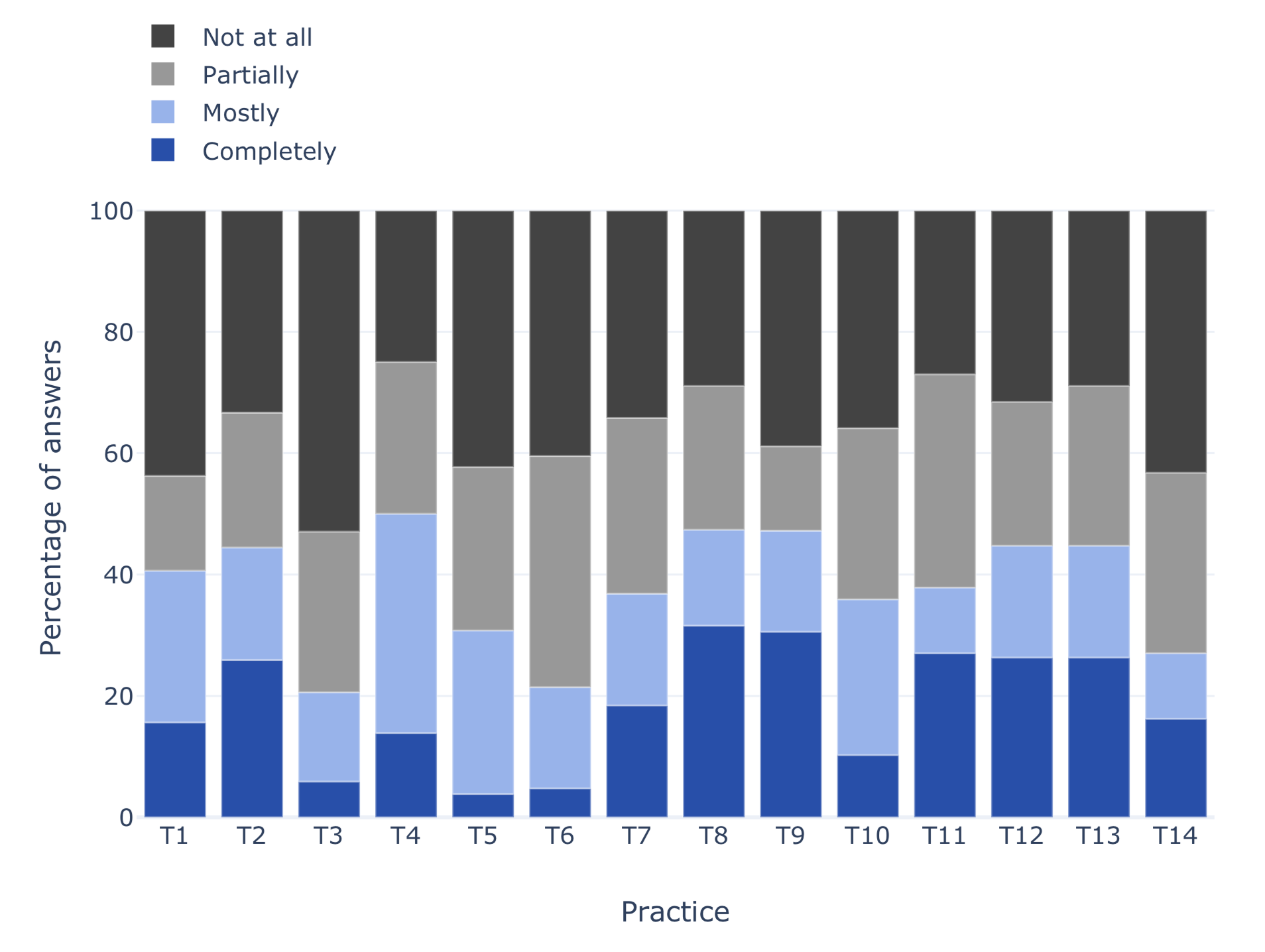
Adoption of practices for trustworthy ML, in the order defined in the catalogue.
Trustworthy ML
Following recent interest by policy makers to address improper use of machine learning (ML), we made efforts to extend our catalogue of practices to include operational practices for trustworthy ML. In particular, we followed the requirements for trustworthy ML developed by the High level expert group on AI from the European Commission, which defines trustworthy AI as being lawful, ethical and robust, and defines 7 key requirements for trustworthy AI.
Inspired by these requirements, we searched the literature for engineering practices that can be directly applied by developers, to address ethical and robust development of ML components. In total, we identified 14 new practices, which include topics such as testing for bias, assuring security, or having the application audited by third parties. For all new practices, we summarised the related work into a body of knowledge that follows the same structure as the previous practices from our catalogue, including detailed description, concise statement of intent, motivation, applicability, related practices, and references.
We also extended our survey to measure the adoption of trustworthiness practices by teams developing ML solutions. Unfortunately, we found out that the practices for trustworthy ML have relatively low adoption (as can be seen in the figure above). In particular, practices related to assuring security of ML components have the lowest adoption.
The contributing factors to these results are diverse. For example, most defences against adversarial examples — a known threat to ML components — have been breached. Moreover, research into data poisoning attacks shows that only a small percentage of training data needs to be altered in order to induce malicious behaviours. We believe the lack of “off the shelf” solution to security issues of ML components is the largest contributor factor to our results.
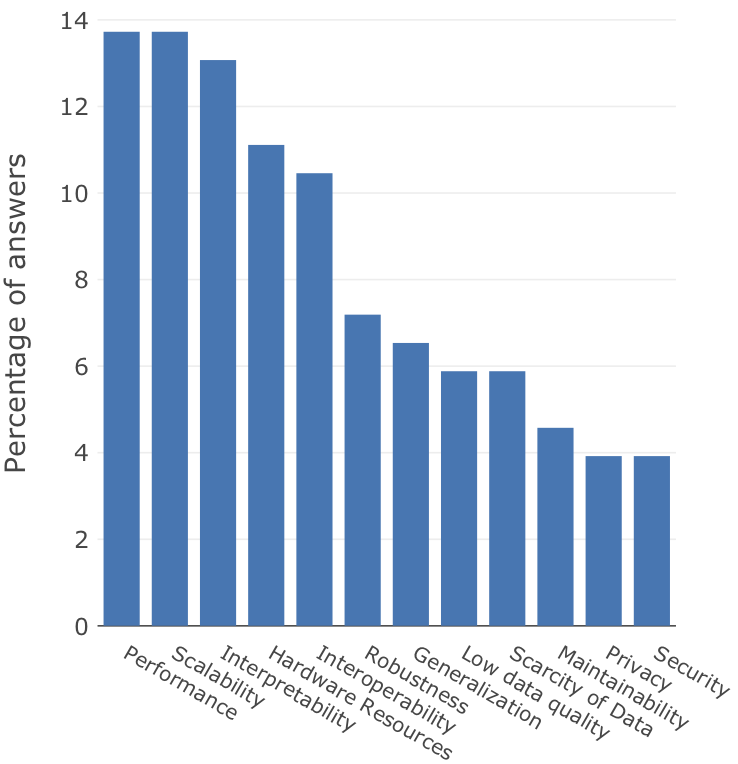
Architectural decision drivers for systems using ML components.
Architecture of ML systems
In a parallel study, in which we investigated how practitioners define the software architecture of systems with ML components, we asked practitioners to rank the most important decision drivers for their systems. Once again, we found out that decision drivers related to trustworthy ML, such as Security, Privacy, or Robustness, were considered less important than more traditional drivers such as Performance or Scalability (as can be seen in the figure above). These results entail that practitioners are still working on solving basic concerns for developing and operationalising the ML components, and tend to neglect the importance of trustworthy ML.
Outlook
We believe that consistent efforts to address ethics and robustness through the eyes of software engineering will enhance the practitioners’ ability to prioritise these requirements, and develop trustworthy ML components. Moreover, we believe that the adoption of trustworthiness-specific and general ML engineering practices is interconnected. For instance, the practice of continuous integration can make the practices for bias testing more effective. Therefore, we are working on defining sets of traditional engineering and trustworthiness related practices that can be directly applied by practitioners to develop more ethical and robust ML components.
Learn more about the practices for trustworthy ML by reading our publication.