Insights into Recent MLOps practices
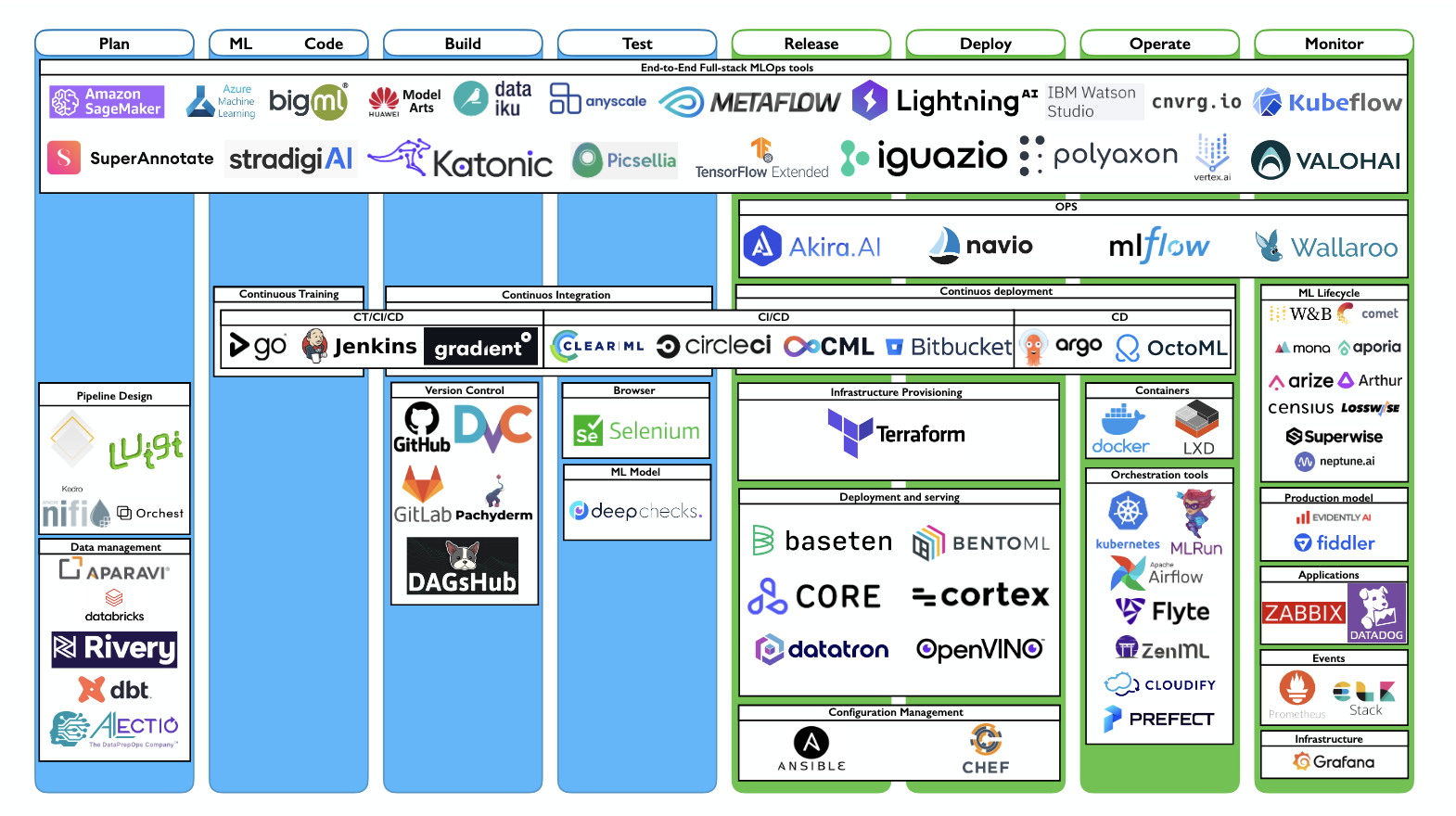
Image from Toward End-to-End MLOps Tools Map A Preliminary Study based on a Multivocal Literature Review
Part of our ongoing exploration into the latest trends in ML engineering best practices we identified five key areas that define the current landscape. This article delves into the second area: MLOps practices, and marks the third part in a series dedicated to examining recent advancements in ML engineering, highlighting emerging challenges, and discussing under-represented topics.
Our systematic analysis of approximately 23 articles reveals that while significant progress has been made in understanding MLOps challenges and adoption patterns, as well as in refining existing practices, there has been a relative scarcity of entirely novel practices. We discuss these findings and assess how they extend, complement, or challenge the existing catalogue of practices.
Challenges and potential solutions:
First, a substantial body of research investigates the challenges, perception, and adoption of MLOps, consistently highlighting gaps in automation, tooling, and quality assurance within ML pipelines [32, 37, 40, 48, 50, 52, 76, 79, 89, 91, 94, 104, 108]. While many of these studies identify issues without developing practices, several promising developments can be translated into actionable practices.
For example, [32, 79] emphasize the importance of defining and adopting a concrete model management strategy, including robust tracking and maintaining lineage and provenance for ML models, ensuring that models are properly identified, named, and labeled.
Furthermore, [7, 32] advocate for establishing continuous data monitoring and validation practices. This is an important, yet often overlooked, topic, as typical MLOps practices tend to prioritize monitoring models in production but frequently neglect data monitoring.
Separately, [108] investigate the behavior of models in production, demonstrating that their performance often cannot be predicted from training data alone. Consequently, they advocate the development of advanced debugging tools for operational environments. These tools could potentially provide a high degree of observability across every part of the ML pipeline, incorporating elements such as telemetry, logs, traces, dashboards, and explainability & trust metrics. Such comprehensive insights can empower engineers to diagnose model issues effectively and facilitate better alignment between technical teams and non-technical stakeholders.
Additionally, [76] address the challenges of scaling ML operations, particularly for smaller organizations. They recommend developing a detailed scaling plan that encompasses not only financial considerations and resource allocation but also a thorough assessment of associated risks and their mitigation strategies.
While their operationalization is not entirely clear, these challenges and their potential solutions represent promising extensions to the existing catalogue of practices, addressing gaps in model management, data monitoring, and the operationalization of debugging tools.
Maintenance & Artifact versioning
A second area identified concerns model maintenance and the versioning and tracing of ML artifacts. This includes strategies for managing the lifecycle of data and models, and their associated components.
For example, [26] propose a technique that enables the reuse of previously trained models for similar data distributions, thereby reducing the need for unnecessary retraining and saving computational resources.
Furthermore, [16] explore how model management can be integrated with datasets and code within larger organizational environments. They introduce the concept of Model lake, an approach analogous to data lakes, where all relevant model artifacts, including versions, metadata, associated data, and code, are centrally stored and managed. This facilitates comprehensive tracking and accessibility.
Separately, [104] investigate the impact of various model export formats on interoperability and deployment. Their findings suggest that adopting ONNX (Open Neural Network Exchange) as a standard practice can improve the portability and deployment efficiency of machine learning models across different frameworks and hardware.
Complementing these conceptual approaches, specific tools are being developed to further improve model management. For example, [71] introduce git-theta, a Git-like version control system specifically designed for models. This system tracks changes at the level of model parameters, enabling communication-efficient checkpointing and providing the ability to track the evolution of weight matrices over time.
Similarly, [68] propose Mgit, a system focused on versioning models by recording provenance and lineage information across different iterations. Mgit also incorporates optimizations for efficient model storage, and proves particularly valuable for tracing model provenance in complex scenarios, such as fine-tuning foundational models developed by external entities.
Together with the model management strategies identified by [32, 79], these developments suggest the emergence of a novel practice for artifact management that can improve the existing catalogue of practices.
Responsible AI
Third, the growing emphasis on Responsible AI (RAI), highlighted in the second article as well, impacts MLOps practices, with researchers and practitioners proposing concrete methods for operationalizing RAI principles.
Specifically, [72] explore various design patterns for responsible MLOps pipelines. These include developing an ethical monitoring system and an ethics patcher, integrating AI ethics auto-testing directly into the pipeline, while [94] advocate for advancing the technological stack towards using zero-trust AI architectures or implementing sophisticated data leakage prevention solutions.
These developments represent an expansion of MLOps scope beyond more traditional performance and reliability concerns, introducing the RAI dimensions that the current practice catalogue does not integrate systematically into operational practices.
Tooling
Last, comprehensive tooling ecosystems are a fundamental pillar for MLOps implementation. While recommending specific tools without organizational context can be challenging due to varying requirements and constraints, [79] provide a comprehensive mapping of end-to-end MLOps tools that can guide practitioners in making informed decisions about their technology stack (an illustration of this mapping is provided in the image above).
What is missing?
While the current focus in MLOps research and practice remains predominantly on understanding fundamental challenges and adoption patterns, several areas continue to be underexplored, particularly as the field evolves toward more complex and large-scale systems.
Scale Challenges in Modern AI Systems
First, there is a notable gap in addressing the operational challenges posed by large-scale model inference, particularly for LLMs, Multimodal LLMs, and other foundation models. These systems present computational, memory, and latency requirements that more traditional practices were not designed to handle. Issues such as efficient model serving at scale, dynamic resource allocation for variable workloads, cost optimization for inference-heavy applications, and managing the complexity of distributed inference across multiple GPUs or cloud regions remain largely unaddressed in the analyzed literature.
Intersection of Scale and Responsible AI
Second, the intersection of scale and RAI presents complex challenges that are inadequately covered in existing research. Operationalizing AI systems that serve millions of users introduces unique ethical and fairness considerations that go beyond traditional bias detection and mitigation strategies (e.g., multi-linguistic contexts, cultural differences, etc.). When models interact with diverse global user bases, biases can manifest in varied and context-dependent ways, requiring sophisticated monitoring and intervention mechanisms.
Cost management
Third, the financial implications of operating large-scale AI systems present a challenge that remains underexplored. The cost structure of modern AI systems, particularly LLMs and foundation models, differs from other ML applications, with inference costs often exceeding training expenses.
Organizations face challenges in predicting and controlling costs when deploying models that require thousands of GPU hours for inference, especially with variable user loads. The complexity is amplified by the need to balance cost optimization with performance – where techniques like model quantization or pruning can reduce costs but may compromise performance for some user groups.
Additionally, the lack of standardized cost monitoring frameworks designed for foundation model deployments leaves organizations without adequate tools to manage AI infrastructure expenses effectively.
Conclusions
Our analysis of recent literature reveals a field in transition, characterized more by refinement and extension of existing practices than by fundamentally novel approaches. This reflects the natural maturation of MLOps as a discipline.
The identified developments – e.g., improved model management strategies and artifact versioning systems, or the integration of Responsible AI principles – represent meaningful extensions to the existing catalogue of practices.
However, our analysis highlights significant blind spots that current research has yet to address. The operational challenges of large-scale AI systems – particularly LLMs and foundation models – expose interesting areas for future exploration. Issues of scale, cost management, and the intersection of RAI with global deployment represent areas where both research and practice lag behind.
Notes
The reference notation is based on the references available in this article.